本文给大家带来工程师的自我修养,一些在 review 细节中不能直接使用的原则。更像是一种信念和自我约束。带着这些信念去编写、review 代码,把这些信念在实践中传递下去,将是极有价值的。

作者 | 林强 责编 | 夏萌
出品 | 腾讯云开发者

偏执
对代码细节偏执的观念,是我自己提出的新观点。在研发质量不高的当下,很要必要普及这个观念。在一个系统不完善、时间安排荒谬、工具可笑、需求不可能实现的世界里,让我们安全行事吧。就像伍迪-艾伦说的:“当所有人都真的在给你找麻烦的时候,偏执就是一个好主意。”
对于一个方案,一个实现,请不要说出“好像这样也可以”。你一定要选出一个更好的做法,并且一直坚持这个做法,并且要求别人也这样做。既然他来让你 review 了,你就要有自己的偏执,你一定要他按照你觉得合适的方式去做。当然,你得有说服得了自己,也说服得了他人的理由,即使只有一点点。偏执会让你的世界变得简单,团队协作变得简单。特别当你身处一个编码质量低下的团队的时候,你至少能说,我是一个务实的程序员。
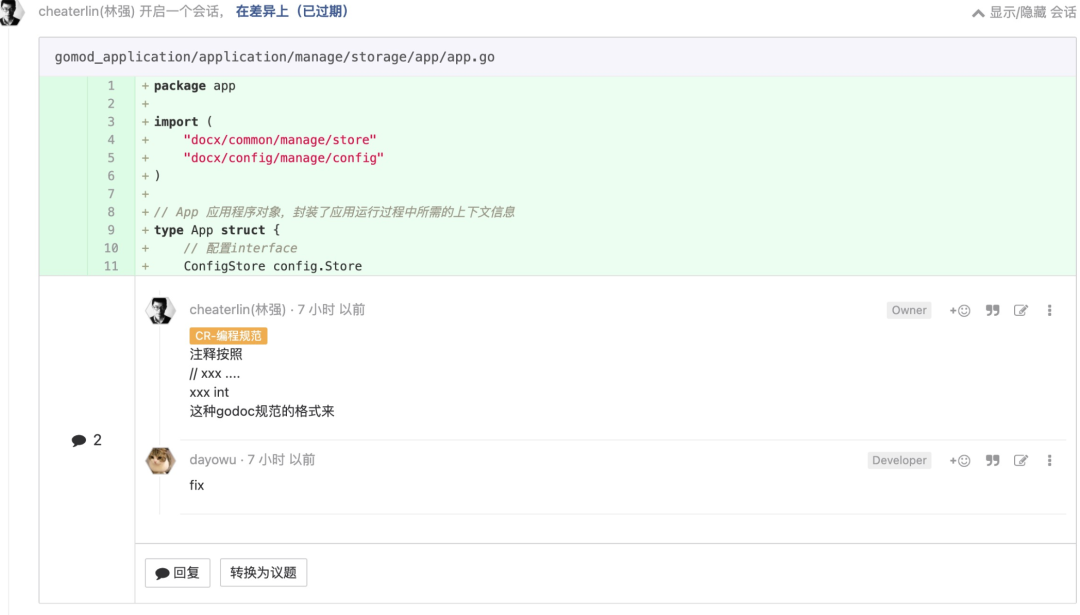

控制软件的熵是软件工程的重要任务之一
熵是个物理学概念,大家可能看过诺兰的电影《信条》。简单来说,熵可以理解为“混乱程度”。我们的项目,在刚开始的几千行代码,是很简洁的。但是,为什么到了 100w 行,我们常常就感觉“太复杂了”?比如老旧代码库开始做大面积重构的时候,往往会发现无数 crash。其中一个重要原因,就是“混乱程度”太高了。“混乱程度”,理解起来还是比较抽象,它有很多其他名字。“hard code 很多”、“特殊逻辑很多”“定制化逻辑很多”。再换另一个抽象的说法,“我们面对一类问题,采取了过多的范式和特殊逻辑细节去实现它”。
熵,是一点点堆叠起来的,在一个需求的 2000 行代码更改中,你可能就引入了一个不同的范式,打破了之前的通用范式。在微观来看,你觉得你的代码是“整洁干净”的。就像一个已经穿着好看的红色风衣的人,你隔一天让他接着穿上一条绿色的裤子,这还干净整洁么?熵,在不断增加,我们需要做到以下几点,不然你的团队将在希望通过重构来降低项目的熵的时候尝到恶果,甚至放弃重构,让熵不断增长下去。
▶︎ 如果没有充分的理由,始终使用项目规范的范式对每一类问题做出解决方案。
▶︎ 如果业务发展发现老的解决方案不再优秀,做整体重构。
▶︎ 项目级主干开发,对重构很友好,让重构变得可行。(客户端很容易实现主干开发)。
▶︎ 务实地讲,重构已经不可能了。那么,你们可以谨慎地提出新的一整套范式。重建它。
▶︎ 禁止 hardcode,特殊逻辑。如果你发现只有特殊逻辑容易实现需求,否则很难。那么往往意味着架构已经出现问题了,你和你的团队应该深入思考这个问题,而不是轻易加上一个特殊逻辑。
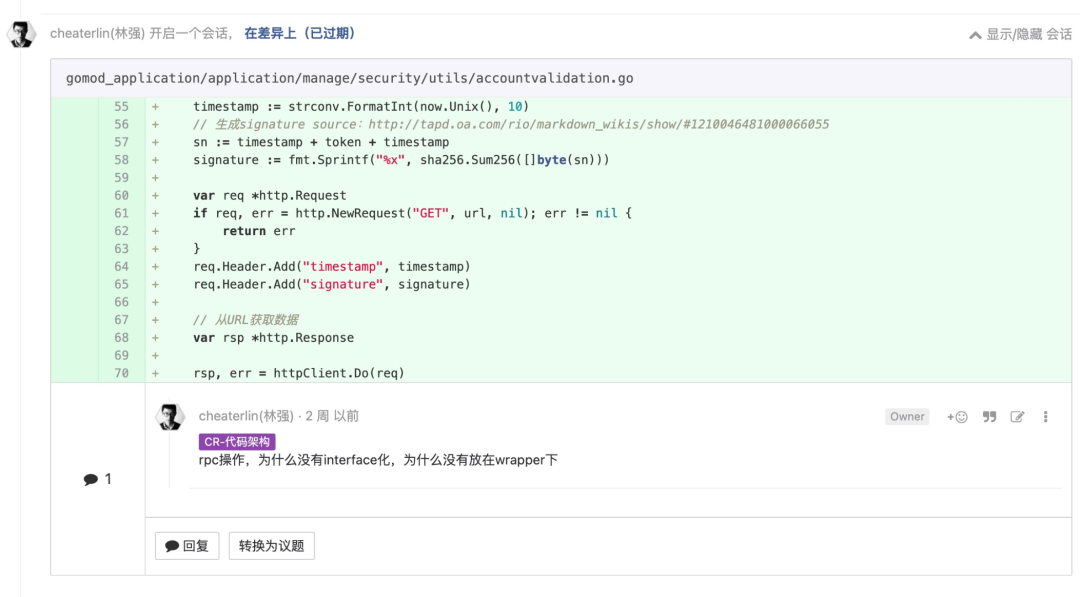
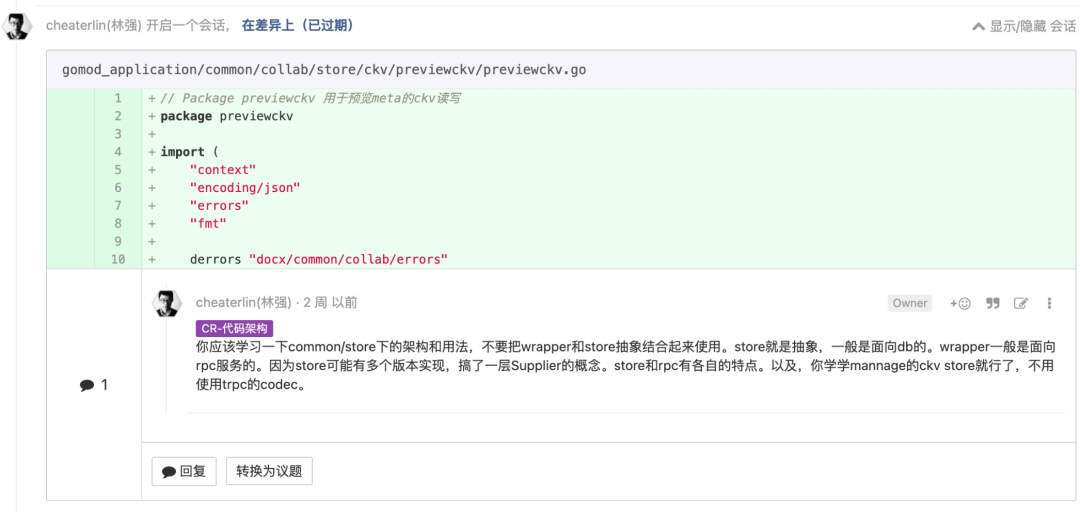

为测试做设计
现在我们在做“测试左移”,让工程师编写自动化测试来保证质量。测试工程师的工作更多的是类似 Google SET(Software Engineer In Test, 参考《Google 软件测试之道》)的工作。工作重心在于测试编码规范、测试编码流程、测试编码工具、测试平台的思考和建设。测试代码,还是得工程师来做。
为方法写一个测试的考虑过程,使我们得以从外部看待这个方法,这让我们看起来是代码的客户,而不是代码的作者。很多同学感觉很难受。这是必然的。因为你在代码设计的时候,并没有把“容易测试”考虑进去,可测试性不强。如果工程师在开发逻辑的过程中,就同时思考着这段代码怎样才能轻松地被测试。那么,这段写就的代码,同时可读性、简单性都会得到保障,经过了良好的设计,而不仅仅是“能工作”。
我觉得,测试获得的主要好处发生在你考虑测试及编写测试的时候,而不是在运行测试的时候!在编码的时候同时让思考怎么测试的思维存在,会让编写高质量的代码变得简单,在编码时就更多地考虑边界条件、异常条件,并且妥善处理。仅仅是抱有这个思维,不去真地编写自动化测试,就能让代码的质量上升,代码架构的能力得到提升。
硬件工程出 bug 很难查,bug 造成的成本很高,每次都要重新做一套模具、做模具的工具。所以硬件工程往往有层层测试,极早发现问题,尽量保证简单且质量高。我们可以在软件上做同样的事情。与硬件工程师一样,从一开始就在软件中构建可测试性,并且尝试将每个部分连接在一起之前,对他们进行彻底的测试。
这个时候有人会说,TDD 就是这样,让你同时思考编码架构和测试架构。我对 TDD 的态度是: 它不一定就是最好的。测试对开发的驱动,绝对有帮助。但是,就像每次驱动汽车一样,除非心里有一个目的地,否则就可能会兜圈子。TDD 是一种自底向上的编程方法。但是,适当的时候使用自顶向下设计,才能获得一个最好的整体架构。很多人处理不好自顶向下和自底向上的关系,结果在使用 TDD 的时候发现举步维艰、收效甚微。
以及,如果没有强大的外部,“以后再测”实际上意味着“永远不测”。大家务实一点,在编码时就考虑怎么测试。不然,你永远没有机会考虑了。当面对着测试性低的代码,需要编写自动化测试的时候,你会感觉很难受。

尽早测试, 经常测试, 自动测试
一旦代码写出来,就要尽早开始测试。这些小鱼的恶心之处在于,它们很快就会变成巨大的食人鲨,而捕捉鲨鱼则相当困难。所以我们要写单元测试,写很多单元测试。
事实上,好项目的测试代码可能会比产品代码更多。生成这些测试代码所花费的时间是值得的。从长远来看,最终的成本会低得多,而且你实际上有机会生产出几乎没有缺陷的产品。
另外,知道通过了测试,可以让你对代码已经“完成”产生高度信心。

项目中使用统一的术语
如果用户和开发者使用不同的名称来称呼相同的事物,或者更糟糕的是,使用相同的名称来代指不同的事物,那么项目就很难取得成功。
DDD(Domain-Driven Design)把“项目中使用统一的术语”做到了极致,要求项目把目标系统分解为不同的领域(也可以称作上下文)。在不同的上下文中,同一个术语名字意义可能不同,但是要项目内统一认识。比如证券这个词,是个多种经济权益凭证的统称,在股票、债券、权证市场,意义和规则是完全不同的。当你第一次听说“涡轮(港股特有金融衍生品,是一种股权)”的时候,是不是瞬间蒙圈,搞不清它和证券的关系了。买“涡轮”是在买什么鬼证劵?
在软件领域是一样的。你需要对股票、债券、权证市场建模,你就得有不同的领域,在每个领域里有一套词汇表(实体、值对象),在不同的领域之间,同一个概念可能会换一个名字,需要映射。如果你们既不区分领域,甚至在同一个领域还对同一个实体给出不同的名字。那,你们怎么确保自己沟通到位了?写成代码,别人如何知道你现在写的“证券”这个 struct 具体是指的什么?

不要面向需求编程
需求不是架构;需求无关设计,也非用户界面;需求就是需要的东西。需要的东西是经常变化的,是不断被探索,不断被加深认识的。产品经理的说辞是经常变化的。当你面向需求编程,你就是在依赖一个认识每一秒都在改变的女/男朋友——你将身心俱疲。
我们应该面向业务模型编程。现在,我给你推荐一个工具,DDD(Domain-Driven Design),面向领域驱动设计。它能让你对业务更好地建模,让对业务建模变成一个可拆解的执行步骤,仅仅需要少得多的智力和经验。区分好领域上下文,思考明白它们之间的关系,找到领域下的实体和值对象,找到和模型贴合的架构方案。这些任务,让业务建模变得简单。
当我们面向业务模型编程,变更的需求就变成了——提供给用户他所需要的业务模型的不同部分。我们不再是在不断地 change 代码,而是在不断地 extend 代码,逐渐做完一个业务模型的填空题。

写代码要有对于“美”的追求
Google 的很多同学说(至少 hankzheng 这么说),软件工程=科学+艺术。当前业界,很多人,不讲科学。工程学,计算机科学,都不管。就喜欢搞“巧合式编程”。刚好能工作了,打完收工,交付需求。绝大多数人,根本不追求编码、设计的艺术。对细节的好看,毫无感觉。对于一个空格、空行的使用,毫无逻辑,毫无美感。用代码和其他人沟通,连基本的整洁、合理都不讲。根本没想过,别人会看我的代码,我要给代码“梳妆打扮”一下,整洁大方,美丽动人,还极有内涵。“窈窕淑女,君子好逑”,我们应该对别人慷慨一点,你总是得阅读别人的代码的。大家都对美有一点追求,就是互相都慷慨一些。
很无奈,我把对美的追求说得这么“卑微”,必须要由“务实的需要”来构建必要性。而不是每个工程师发自内心的,像对待漂亮的异性、好的音乐、好的电影一样的发自内心的需要它。认为代码也是取悦别人、取悦自己的东西。
如果我们想做一个有尊严、有格调的工程师,我们就应该把自己的代码、劳动的产物,当成一件艺术品去雕琢。务实地追求效率,同时也追求美感。效率产出价值,美感取悦自己。不仅仅是为了一口饭,同时也把工程师的工作当成自己一个快乐的源头。工作不再是 overhead,而是 happiness。此刻,你做不到,但是应该有这样的追求。当我们都有了这样的追求,有一天,我们会能像 Google 一样做到的 。
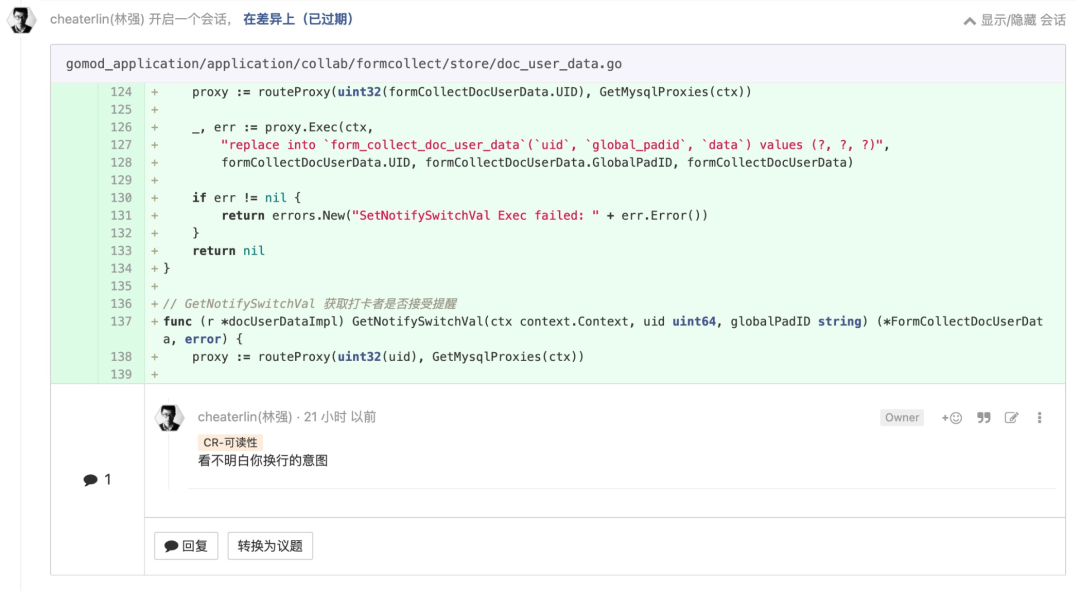

应用程序框架是实现细节
以下是《整洁架构之道》的原文摘抄:
我们与框架作者之间的关系是非常不对等的。我们要采用某个框架就意味着自己要遵守一大堆约定,但框架作者却完全不需要为我们遵守什么约定。
请仔细想想这一关系,当我们决定采用一个框架时,就需要完整地阅读框架作者提供的文档。在这个文档中,框架作者和框架其他用户对我们提出进行应用整合的一些建议。一般来说,这些建议就是在要求我们围绕着框架来设计自己的优秀的系统架构。譬如,框架作者会建议我们基于框架中的基类来创建一些派生类,并在业务对象中引入些框架的工具。框架作者还会不停地催促我们将应用与框架结合得越紧密越好。
对框架作者来说,应用程序与自己的框架耦合是没有风险的。毕竟作为作者,他们对框架有着绝对的控制权,强耦合是应该的。与此同时,作者当然是非常希望我们的应用与其框架紧密结合的,因为这意味着脱离框架会很困难。作为框架作者来说,没有什么比让一堆用户心甘情愿地基于他的框架基类来构建派生类更自豪的事情了。换句话说,框架作者想让我们与框架订终身-这相当于我们要对他们的框架做一个巨大而长期的承诺,而在任何情况下框架作者都不会对我们做出同样的承诺。这种婚姻是单向的。我们要承担所有的风险,而框架作者则没有任何风险。
解决方案是:请不要嫁给框架!
我们可以使用框架-但要时刻警惕,别被它拖住。我们应该将框架作为架构最外圈的一个实现细节来使用,不要让它进入内圈。
如果框架要求我们根据它们的基类来创建派生类,就请不要这样做,我们可以创造一些代理类,同时把这些代理类当作业务逻辑的插件来管理。
另外,不要让框架污染我们的核心代码,应该依据依赖关系原则(DIP),将它们当作核心代码的插件来管理。以 Spring 为例,它作为一个依赖注入框架是不错的。也许我们会需要用 Spring 来自动连接应用程序中的各种依赖关系。这不要紧,但是千万别在业务对象里到处写 @autowired 注释。业务对象应该对 Spring 完全不知情才对。反之,我们也可以利用Spring将依赖关系注入到 Main 组件中,毕竟 Main 组件作为系统架构中最低层、依赖最多的组件,它依赖于 Spring 并不是问题。
对,DIP 大发神威。我觉得核心做法就是:
▶︎ 核心代码应该通过 DIP 来让它不要和具体框架绑定!它应该使用 DIP(比如代理类),抽象出一个防腐层,让自己的核心代码免于腐坏。
▶︎ 选择一个框架,你不去做防腐层(主要通过 DIP),你就是单方面领了结婚证,你只有义务,没有权利。同学们要想明白。同学们应该对框架本身是否优秀,是否足够组件化,它本身能否在项目里做到可插拔,做出思考和设计。
trpc-go 对于插件化这事儿,做得还不错,大家会积极地使用它。trpc-cpp 离插件化非常远,它自己根本就成不了一个插件,而是有一种要强暴你的感觉,你能凭直觉明显地感觉到不愿意和它定终身。例如,trpc-cpp 甚至强暴了你构建、编译项目的方式。当然,这很多时候是 c++语言本身的问题。
“解耦”、“插件化”就是 Golang 语言的关键词。大家开玩笑说,C++已经被委员会玩坏了,加入了太多特性。less is more, more means nothing。C++从来都是让别的工具来解决自己的问题,trpc-cpp 可能把自己松绑定到 bazel 等优秀的构建方案。寻求优秀的组件去软绑定,提供解决方案,是可行的出路。我个人喜欢 Rust。但是大家还是熟悉 cpp,我们确实需要一个投入更多人力做得更好的 trpc-cpp。

一切都应该是代码(通过代码去显式组合)
Unix 编程哲学告诉我们: 如果有一些参数是可变的,我们应该使用配置,而不是把参数写死在代码里。在腾讯,这一点做得很好。但是,大人,现在时代又变了。
J2EE 框架让我们看到,组件也可以是通过配置 Java Bean 的形式注入到框架里的。J2EE 实现了把组件也配置化的壮举。但是,时代变了!你下载一个 Golang 编译器,你进入你下载的文件里去看,会发现你找不到任何配置文件。这是为什么?两个简单,但是很多年都被人们忽略的道理:
▶︎ 配置即隐性耦合。配置只有和使用配置的代码组合使用,它才能完成它的工作。它是通过把“一个事情分开两个步骤”来换取动态性。换句话说,它让两个相隔十万八千里的地方产生了耦合!作为工程师,你一开始就要理解双倍的复杂度。配置如何使用、配置的处理程序会如何解读配置。
▶︎ 代码能够有很强的自解释能力,工程师们更愿意阅读可读性强的代码,而不是编写得很烂的配置文档。配置只能通过厚重的配置说明书去解释。当你缺乏完备的配置说明书,配置变成了地狱。
Golang 的编译器是怎么做的呢?它会在代码里给你设定一个通用性较强的默认配置项。同时,配置项都是集中管理的,就像管理配置文件一样。你可以通过额外配置一个配置文件或者命令行参数,来改变编译器的行为。这就变成了,代码解释了每一个配置项是用来做什么的。只有当你需要的时候,你会先看懂代码,然后,当你有需求的时候,通过额外的配置去改变一个你有预期的行为。
逻辑变成了:一开始,所有事情都是解耦的,一件事情都只看一块代码就能明白。代码有较好的自解释性和注解,不再需要费劲地编写撇脚的文档。当你明白之后,你需要不一样的行为,就通过额外的配置来实现。关于怎么配置,代码里也讲明白了。
对于 trpc-go 框架,以及一众插件,优先考虑配置,然后才是代码去指定,部分功能还只能通过配置去指定,我就很难受。我接受它,就得把一个事情放在两个地方去完成:
▶︎ 需要在代码里 import 插件包。
▶︎ 需要在配置文件里配置插件参数。
既然不能消灭第一步,为什么不能是显式 import,同时通过代码+其他自定义配置管理方案去完成插件的配置?当然,插件,直接不需要任何配置,提供代码 Option 去改变插件的行为,是最香的。这个时候,我就真的能把 trpc 框架本身也当成一个插件来使用了。

封装不一定是好的组织形式
封装(Encapsulation),是我上学时刚接触 OOP,惊为天人的思想方法。但是,我工作了一些年头了,看过了不知道多少腐烂的代码。其中一部分还需要我来维护。我看到了很多莫名其妙的封装,让我难受至极。封装,经常被滥用。封装的时候,我们一定要让自己的代码,自己就能解释自己是按照下面的哪一种套路在做封装:
▶︎ 按层封装;
▶︎ 按功能封装;
▶︎ 按领域封装;
▶︎ 按组件封装。
或者,其他能被命名到某种有价值的类型的封装,你要能说出为什么你的封装是必要的,有价值的。必要的时候,你必须要封装。比如,当你的 Golang 函数达到了 80 行,你就应该对逻辑分组,或者把一块过于细节化却功能单一的较长的代码独立到一个函数。同时,你又不能胡乱封装,或者过度封装。是否过度,取决于大家的共识,要 reviwer 能认可你这个封装是有价值的。当然,你也会成为 reviewer,别人也需要获得你的认可。缺乏意图设计的封装,是破坏性的。这会使其他人在面对这段代码时,畏首畏尾,不敢修改它。形成一个腐烂的肉块,并且,这种腐烂会逐渐蔓延开来。
所以,所有细节都是关键的。每一块砖头都被精心设计,才能构建一个漂亮的项目!

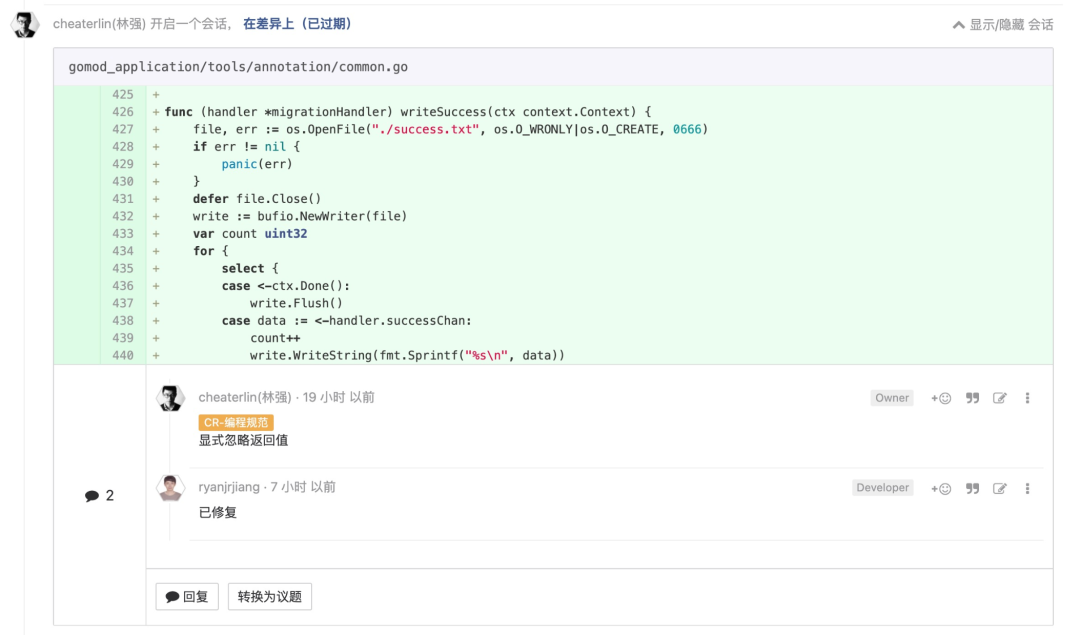
所有细节都应该被显式处理
这是一个显而易见的道理,但是很多同学却毫无知觉。我为需要为深入阅读他们编写的代码的同学默哀一秒。当有一个函数 func F() error,我仅仅是用 F(),没有用变量接收它的返回值。你阅读代码的时候,你就会想,第一开发者是忘记了 error handling 了,还是他思考过了,他决定不关注这个返回值?他是设计如此,还是这里是个 bug?他人即地狱,维护代码的苦难又多了一分。
我们对于自己的代码可能会给别人带来困扰的地方,都应该显式地去处理,就像写了一篇不会有歧义的文章。如果就是想要忽略错误,“_ = F()”搞定。我将来再处理错误逻辑,“_ = F() // TODO 这里需要更好地处理错误”。在代码里,把事情讲明白,所有人都能快速理解他人的代码,就能快速做出修改的决策。“猜测他人代码的逻辑用意”是很难受且困难的,他人的代码也会在这种场景下,产生被误读。

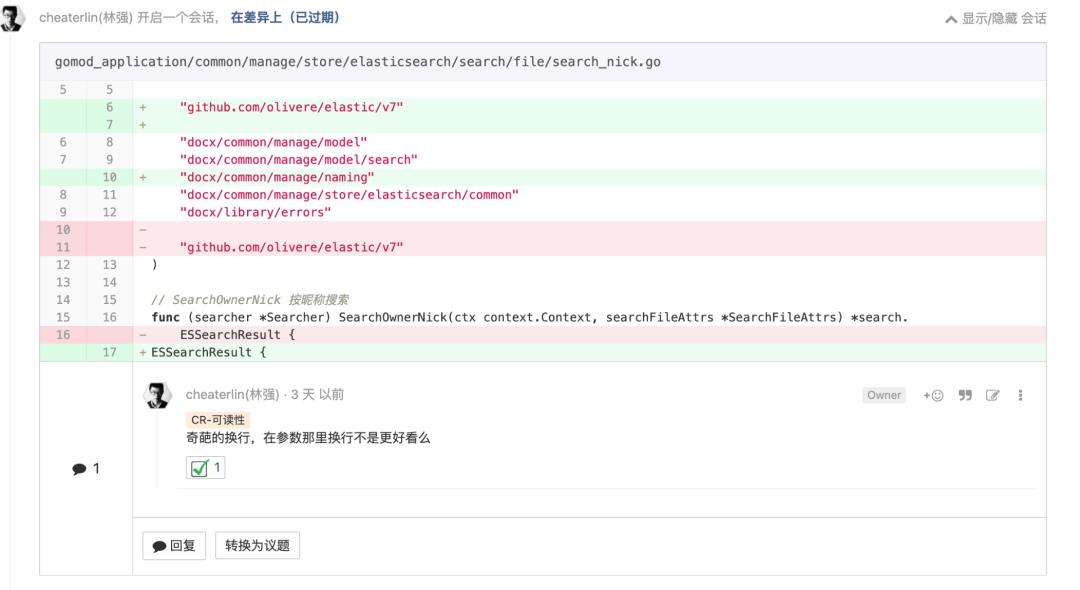
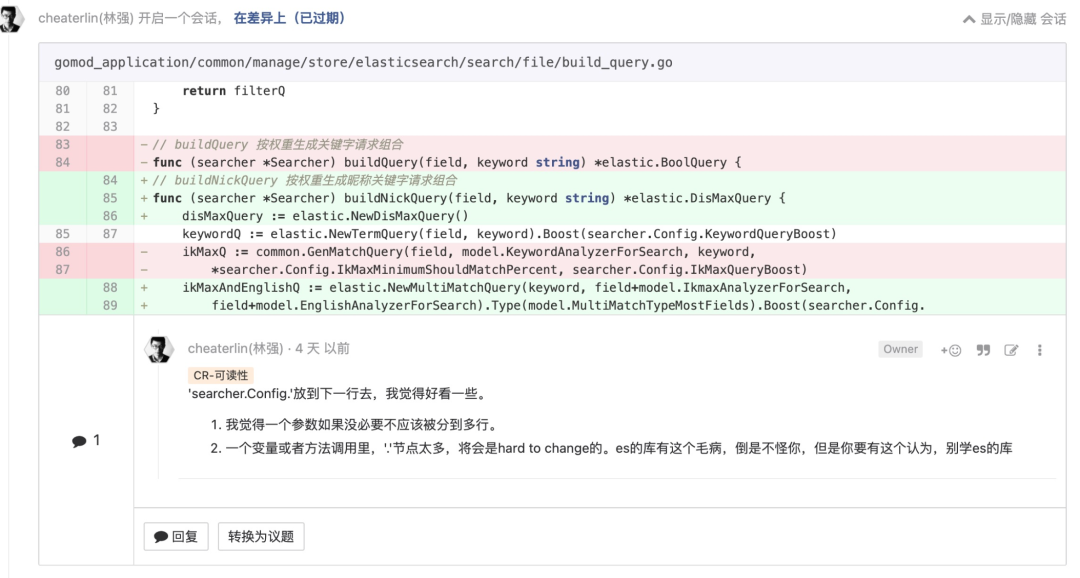
合理注释一些并不“通俗”的逻辑和数值
和“所有细节都应该被显式处理”一脉相承。所有他人可能要花较多时间猜测原因的细节,都应该在代码里提前清楚地讲明白,请慷慨一点。也可能,三个月后的将来,是你回来 eat your own dog food。
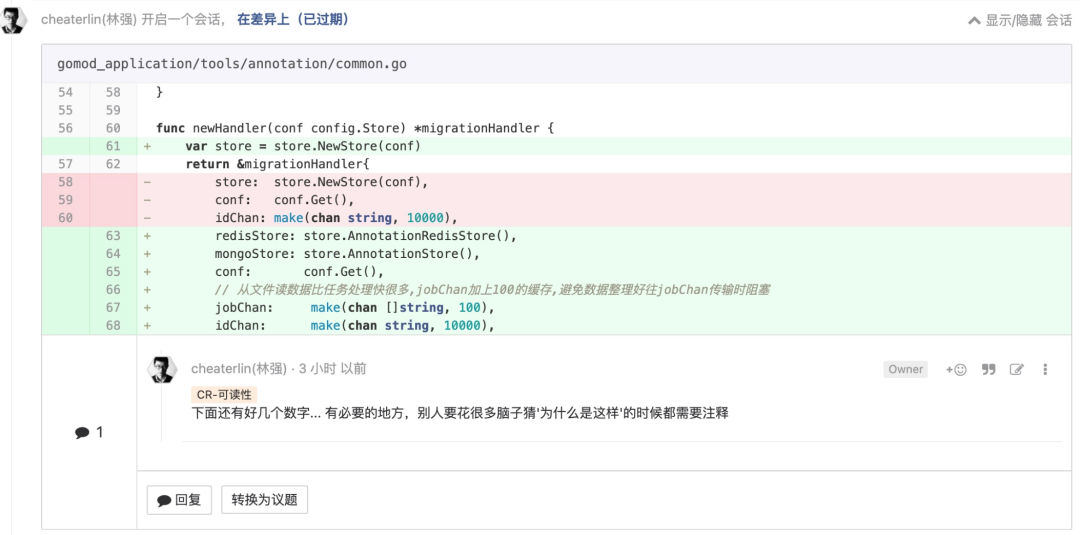

习惯留下 TODO
要这么做的道理很简单,便于所有人能接着你开发——极有可能就是你自己接着自己开发。如果没有标注 TODO 把没有做完的事情标示出来,可能你自己都会搞忘自己有事儿没做完了。留下 TODO 是很简单的事情,我们为什么不做呢?
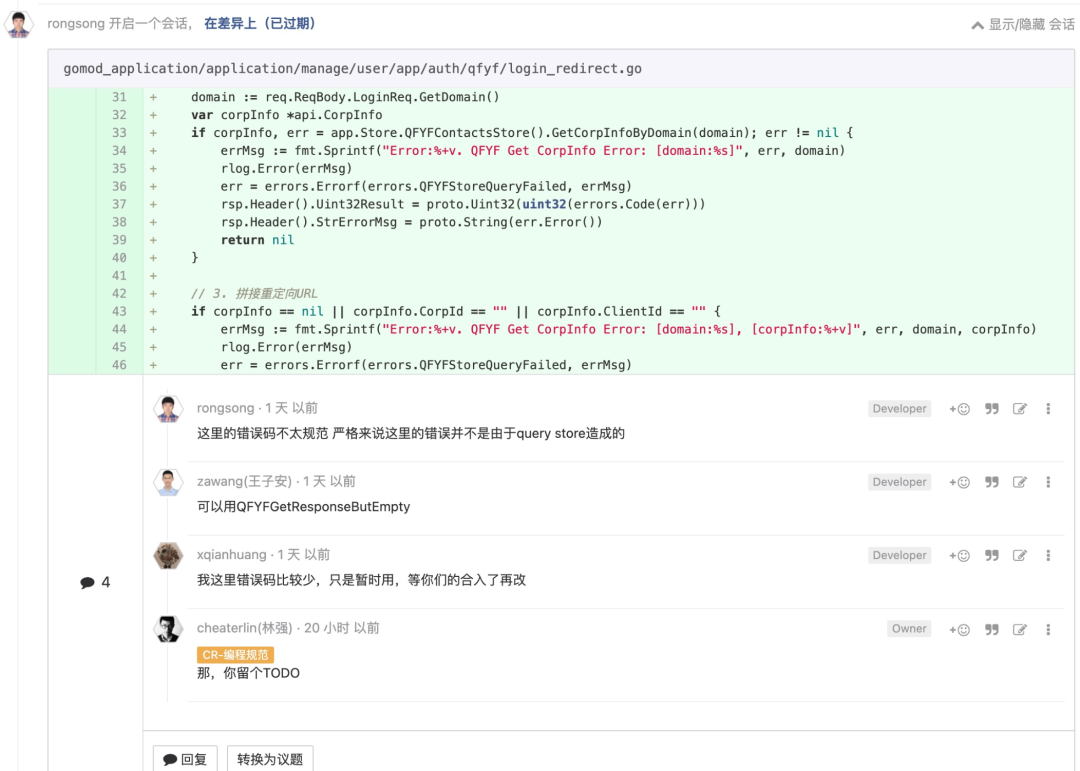

不要丢弃错误信息
即“错误传递原则”。这里给它换个名字——你不应该主动把很多有用的信息给丢弃了。
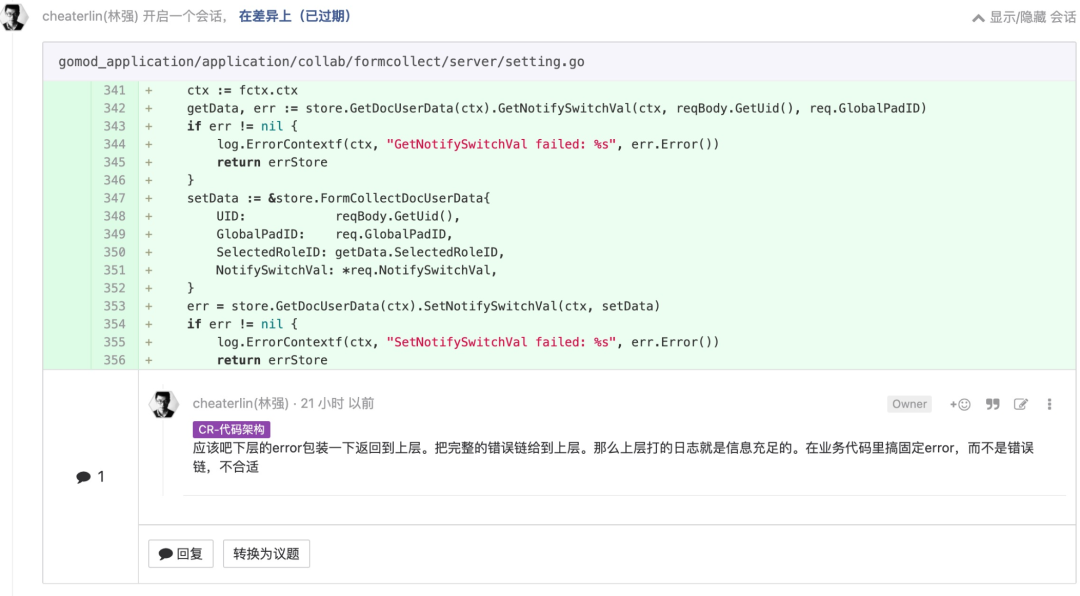

自动化测试要快
在 Google,自动化测试是硬性要求在限定时间内跑完的。这从细节上保障了自动化测试的速度,进而保障了自动化测试的价值和可用性。你真的需要 sleep 这么久?应该认真考量,考量清楚了把原因写下来。当大家发现总时长太长的时候,可以选择其中最不必要的部分做优化。
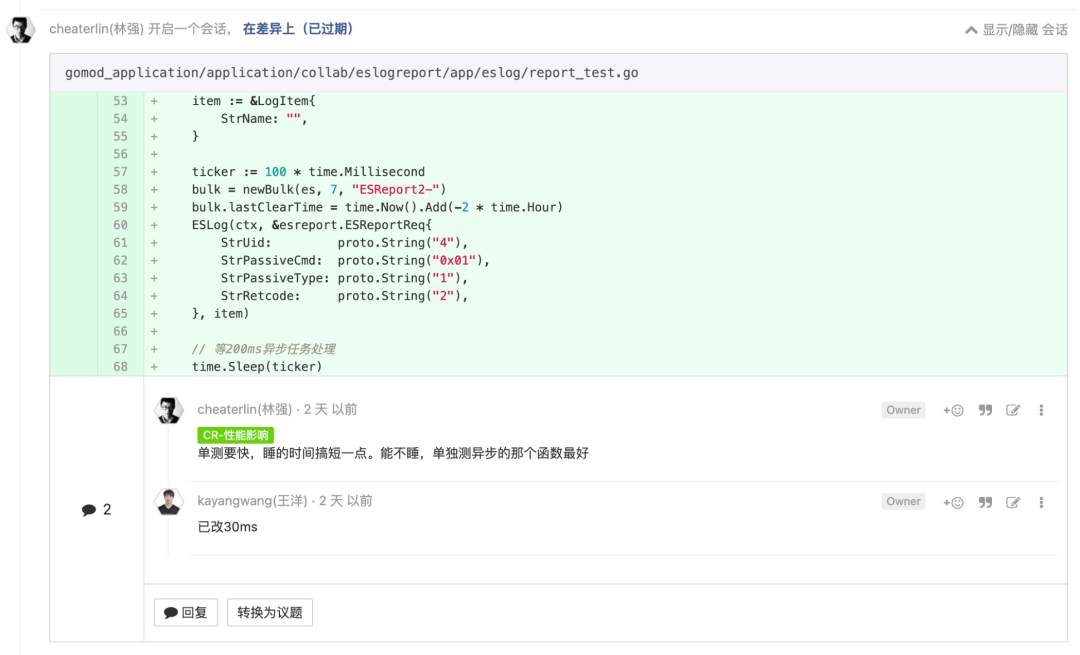

历史有问题的代码, 发现了问题要及时 push 相关人主动解决
这是“控制软件的熵是软件工程的重要任务之一”的表现之一。我们是团队作战,不是无组织无纪律的部队。发现了问题,就及时抛出和解决。让伤痛更少,跑得更快。
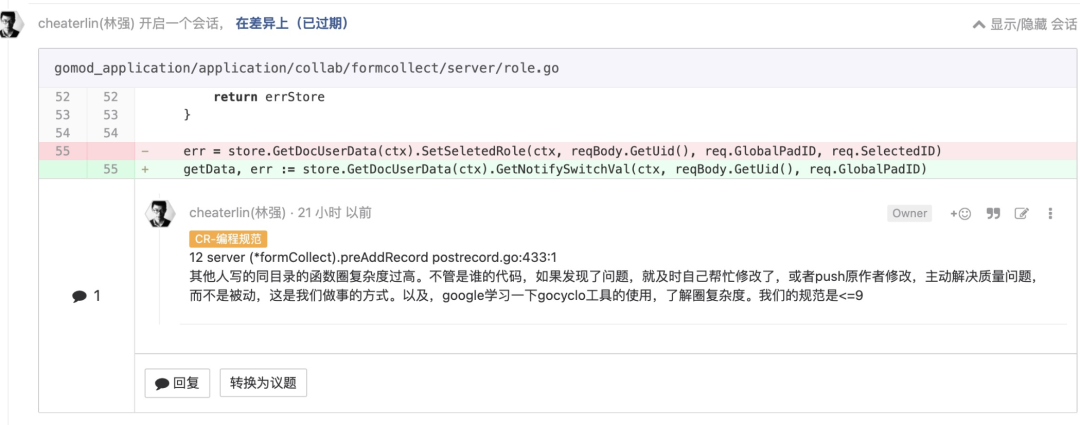

less is more
less is more. 很好理解,这里不再展开阐述。
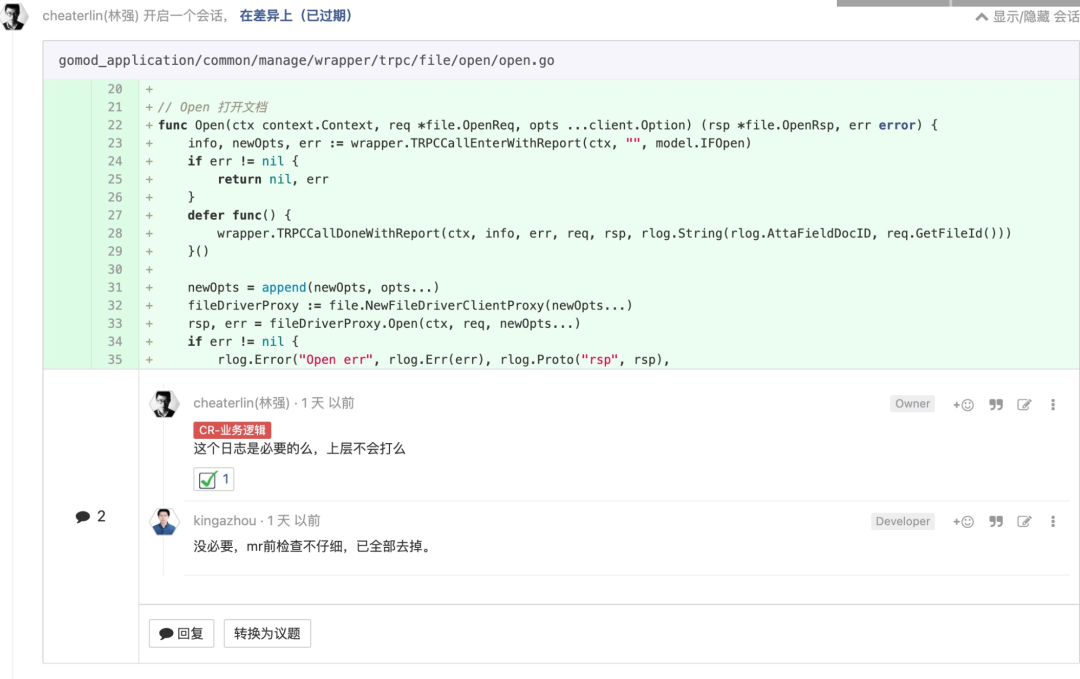

如果打了错误日志, 有效信息必须充足, 且不过多
和“less is more”一脉相承。同时,必须有的时候,就得有,不能漏。
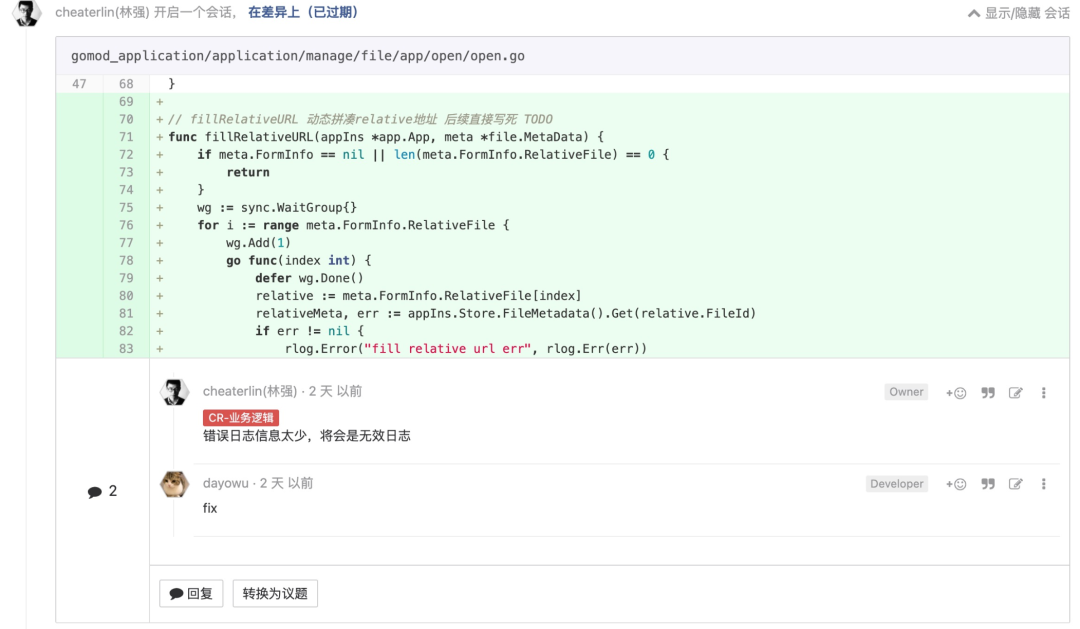

注释要把问题讲清楚, 讲不清楚的日志等于没有
是个简单的道理,和“所有细节都应该被显式处理”一脉相承。
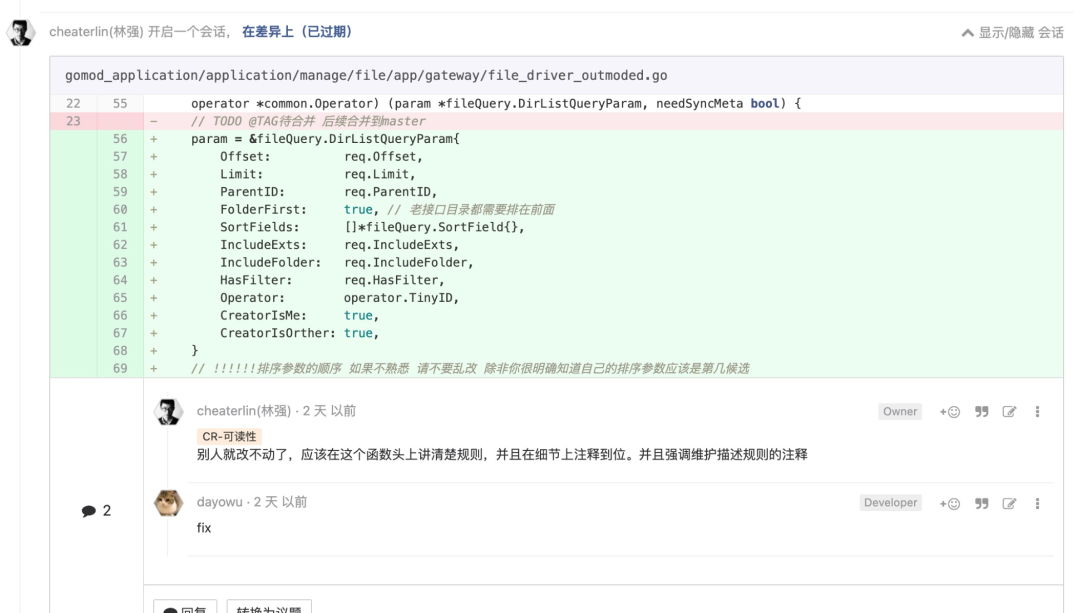

MR 要自己先 review, 不要浪费 reviewer 的时间
你也会成为 reviewer,节省他人的时间,他人也节省你的时间。缩短交互次数,提升 review 的愉悦感。让他人提的 comment 都是“言之有物”的东西,而不是一些反反复复的最基础的细节。这会让他人更愉悦,自己在看 comment 的时候,也更愉悦,更愿意去讨论、沟通。让 code review 成为一个技术交流的平台。
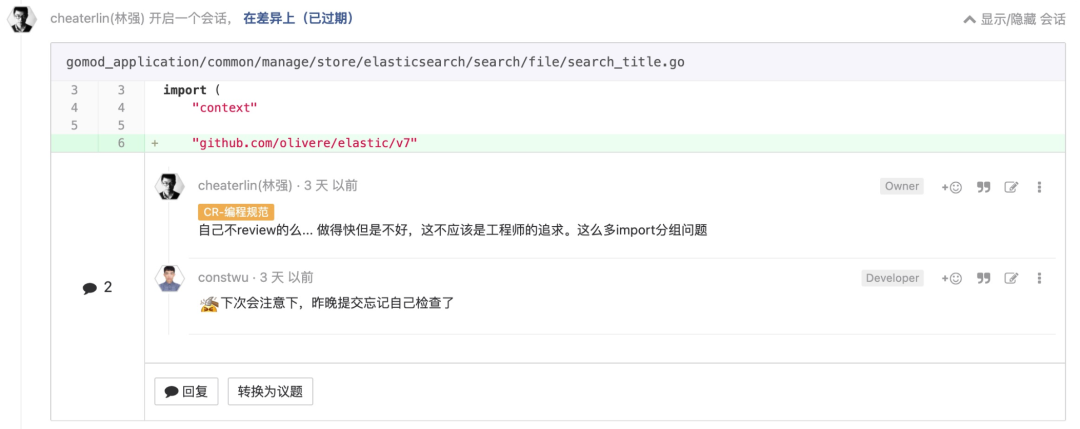

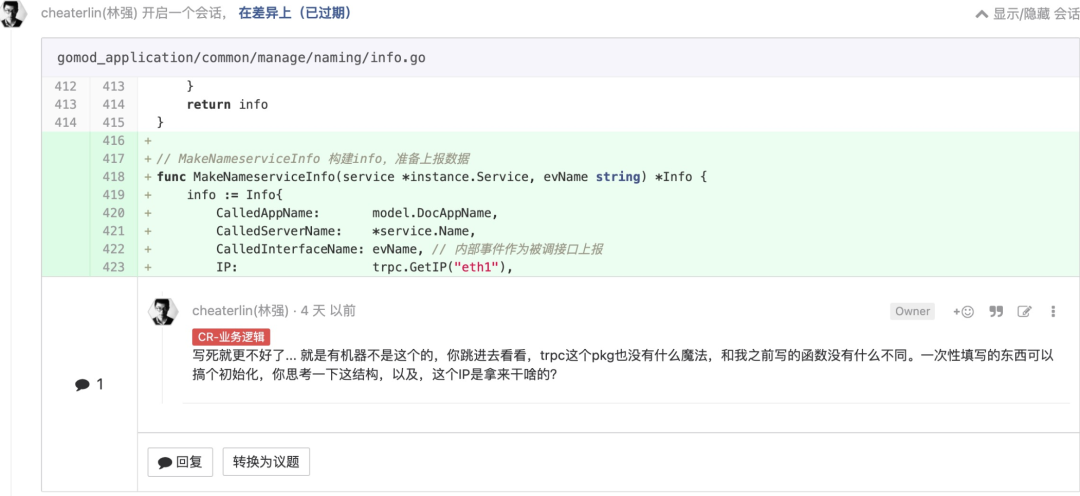
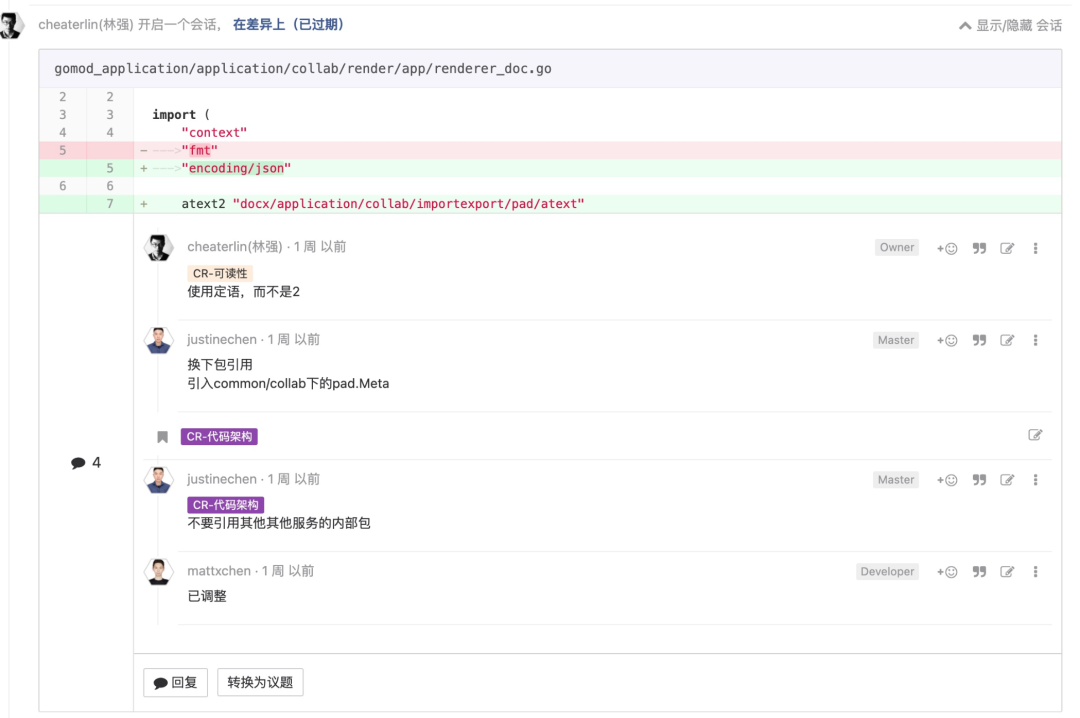
要寻找合适的定语
这个显而易见。但是,同学们就是爱放纵自己?

不要出现特定 IP,或者把什么可变的东西写死
这个和“ETC”一脉相承,我觉得也是显而易见的东西。但是很多同学还是喜欢放纵自己?

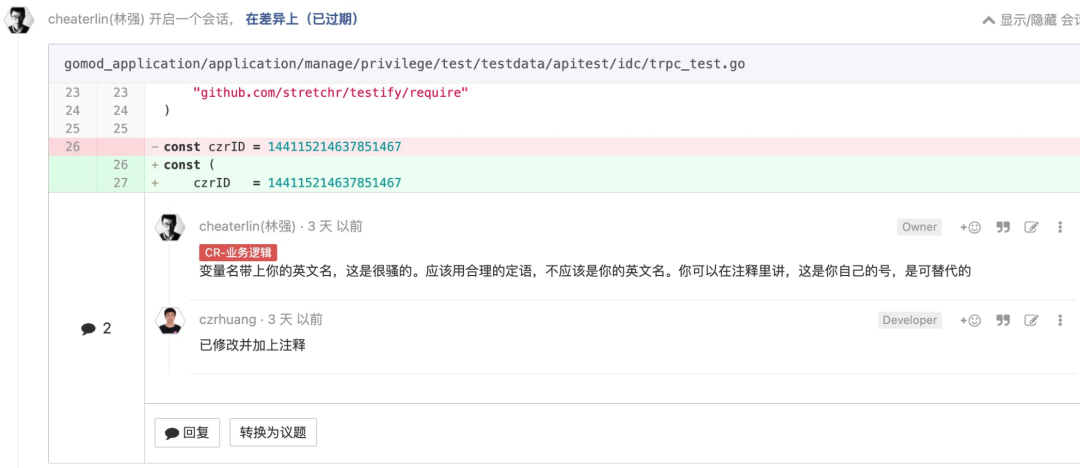
使用定语, 不要 1、2、3、4
这个存粹就是放纵自己了。当然,也会有只能用 1、2、3、4 的时候。但是,你这里,是么?多数时候,都不会是。

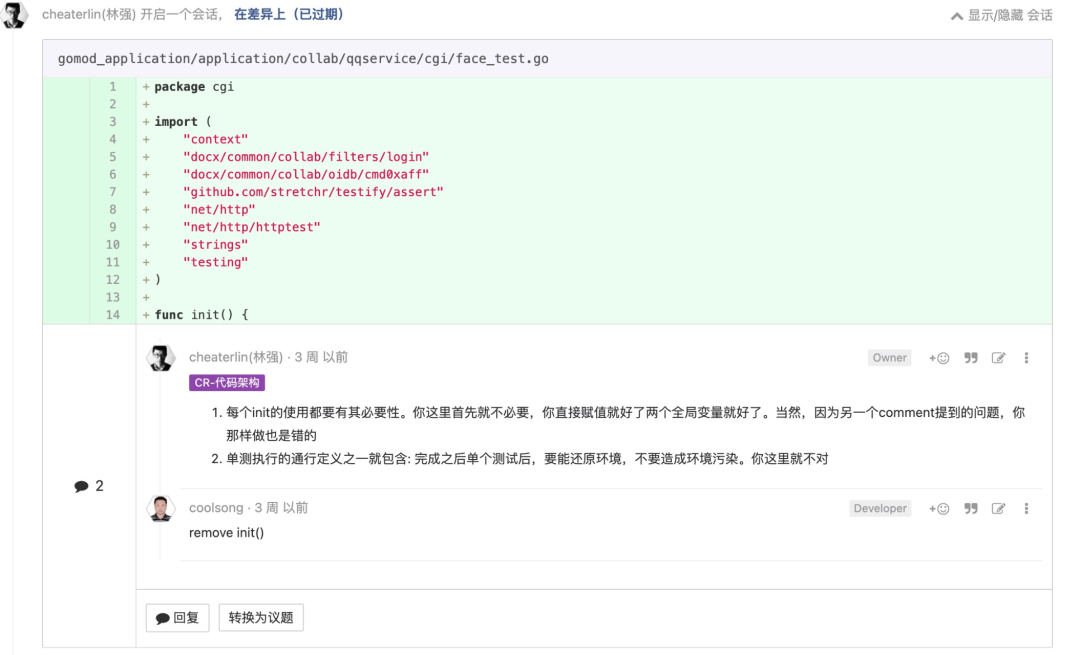
有必要才使用 init
这也显而易见。init 很方便,但是,它也会带来心智负担。

要关注 shadow write
这个很重要,看例子就知道了。但是大家常常忽略,特此提一下。
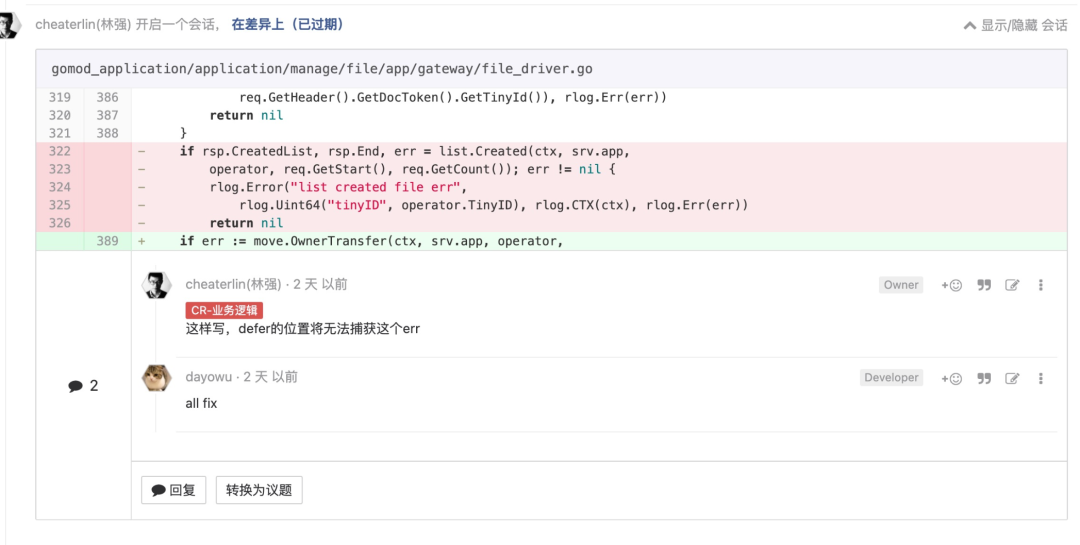

能不耦合接收器就别耦合
减少耦合是我们保障代码质量的重要手段。请把 ETC 原则放在自己的头上漂浮着,时刻带着它思考,不要懒惰。熟能生巧,它并不会成为心智负担。反而常常会在你做决策的时候帮你快速找到方向,提升决策速度。
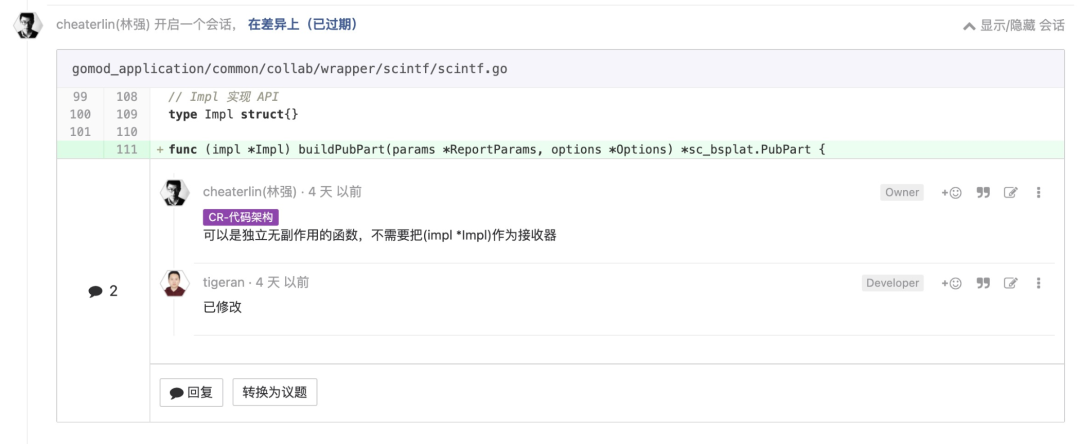

空实现需要注明空实现就是实现
这个和“所有细节都应该被显式处理”一脉相承。这个理念,我见过无数种形式表现出来。这里就是其中一种。列举这个 case,让你印象再深刻一点。

看错题集没多少用, 我们需要教练和传承
上面我列了很多例子,是我能列出来的例子中的九牛一毛。但是,我列一个非常庞大的错题集没有任何用,我也不再例举更多。只有当大家信奉了敏捷工程的美,认可好的代码架构对于业务的价值,才能真正地做到举一反三,理解无数例子,能对更多的 case 自己做出合理的判断。同时,把好的判断传播起来,做到“群体免疫”,最终做好 review,做好代码质量。

展望
希望本文能帮助到需要做好 CR、做好编码,需要培养更多 reviwer 的团队。让你门看到很多原则,吸收这些原则和理念。去理解、相信这些理念。在 CR 中把这些理念、原则传播出去。成为别人的临时教练,让大家都成为合格的 reviwer。加强对于代码的交流,飞轮效应,让团队构建好的人才梯度和工程文化。
写到最后,我发现,我上面写的这些东西都不那么重要了。你有想把代码写得更利于团队协作的价值观和态度,反而是最重要的事情。上面讲的都仅仅是写高质量代码的手段和思想方法。当你认可了“应该编写利于团队协作的高质量代码”,并且拥有对“不利于团队代码质量的代码”嫉恶如仇的态度。你总能找到高质量代码的写法。没有我帮你总结,你也总会掌握!

拾遗
如果你深入了解 DDD,就会了解到“六边形架构”、“CQRS(Command Query Responsibility Segregation,查询职责分离)架构”、“事件驱动架构”等关键词。是 DDD 构建自己体系的基石,这些架构及是细节又是顶层设计,也值得了解一下。