公众号:尤而小屋作者:Peter编辑:Peter

本文主要介绍的是pandas中的一个移动函数:shift。最后结合一个具体的电商领域中用户的复购案例来说明如何使用shift函数。
这个案例综合性很强,除了需要掌握shift函数,你还会复习到以下pandas中的多个函数使用技巧,建议认真阅读、理解并收藏,欢迎点赞呀~
分组统计:groupby
过滤筛选数据:query
排序函数:sort_values
合并函数:concat
字段重命名:rename
缺失值删除:dropna
宝藏函数:apply

Pandas文章连载系列已经到了第20篇,主要分为3类:
基础部分:1-16篇,主要是介绍Pandas中基础和常用操作,比如数据创建、检索查询、排名排序、缺失值/重复值处理等
进阶部分:第17篇开始讲解Pandas中的高级操作方法;后续主要是以时间序列相关为主
对比SQL,学习Pandas:将SQL和Pandas的操作对比起来进行学习
14种方式,34个案例:对比SQL,学习Pandas操作
periods:表示移动的幅度,可正可负;默认值是1,1就表示移动一次。注意这里移动的都是数据,而索引是不移动的,移动之后没有对应值的,就赋值为NaN。
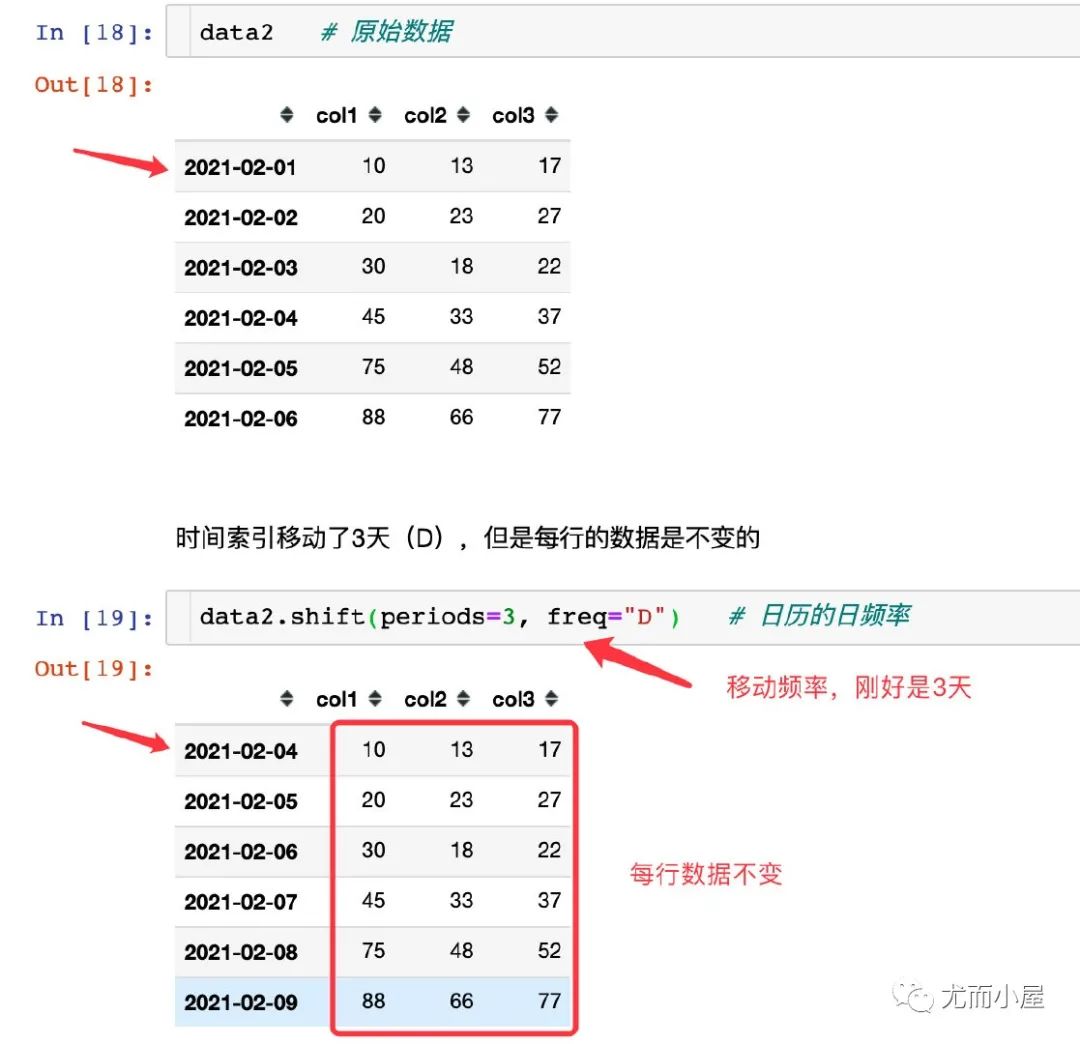
freq:DateOffset, timedelta, or time rule string,可选参数,默认值为None,只适用于时间序列。如果这个参数存在,那么会按照参数值移动时间索引,而数据值没有发生变化。
axis:表示按照哪个轴移动。axis=0表示index,横轴;axis=1表示columns,纵轴
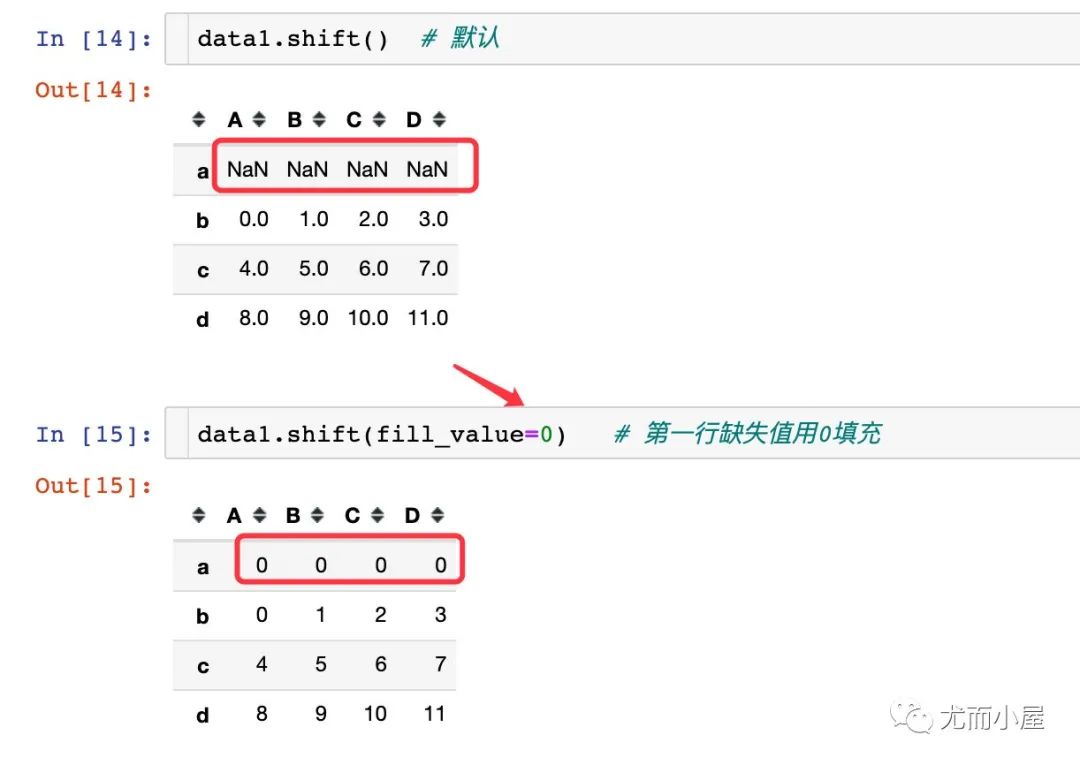
fill_value:表示当我们数据发生了移动之后,产生的缺失值用什么数据填充。如果是数值型的缺失值,用np.nan;如果是时间类型的缺失值,用NaT(not a time)
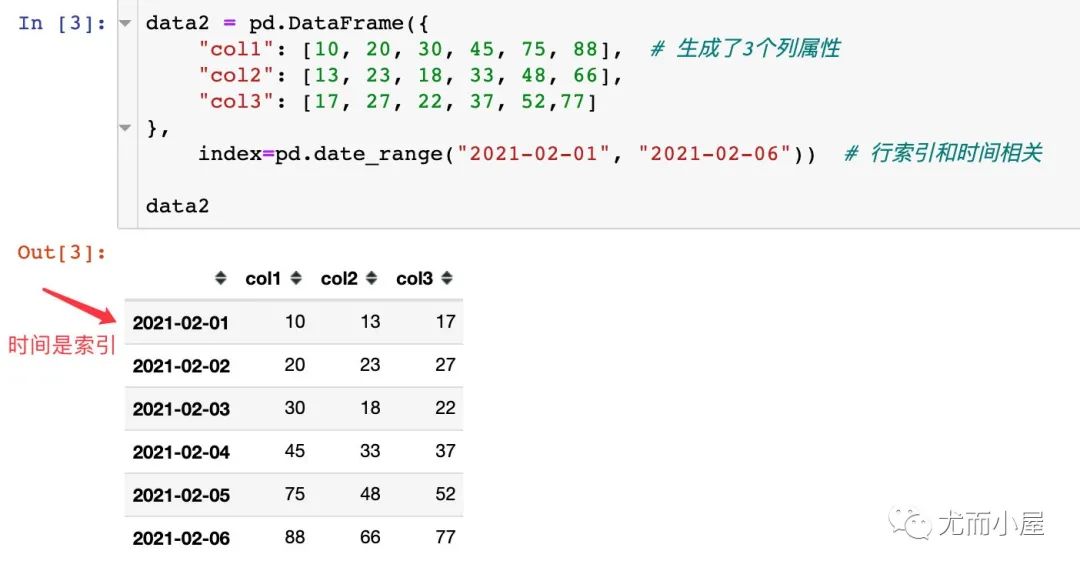
模拟了两份数据,其中一份和时间相关。

另一份是和时间相关的:
表示每次移动的幅度

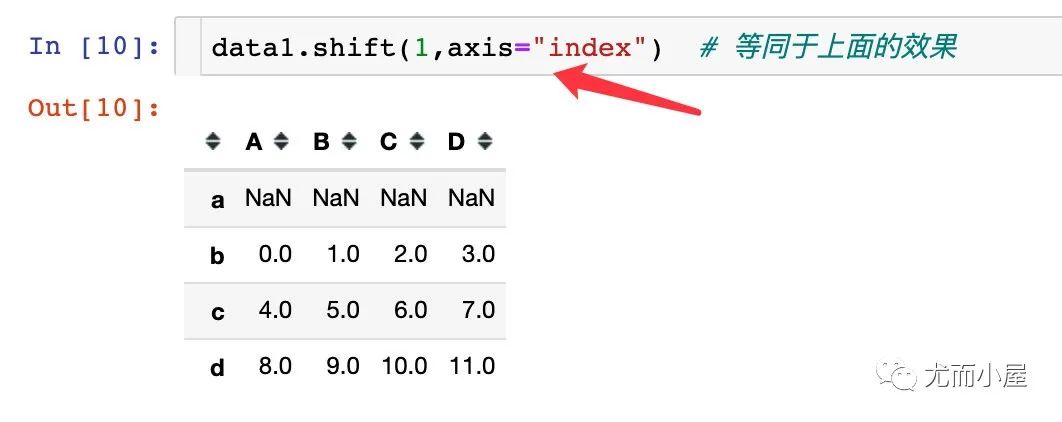
可以看到默认情况下,shift函数是在行方向上移动一个单位

用来表示在哪个方向上进行移动,上面的例子默认是在axis=0,或者表示成:axis="index"

如果我们想在列方向上移动,可以使用axis=1或者axis="columns"

同时移动的幅度是可正可负的:

移动之后缺失值的填充数据

表示移动的频率,专门用于时间序列的移动中

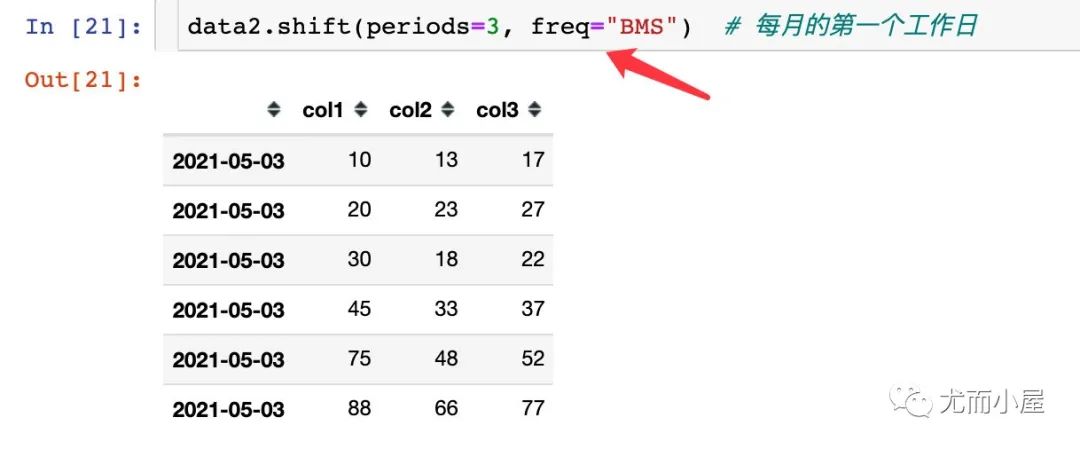
频率
时间序列变化频率有间隔相同的,也有不同的。许多字符串别名被赋予有用的普通时间序列频率。我们将这些别名称为偏移别名。上面的shift函数中使用的就是这些别名,具体如下表所示:
什么是用户的复购周期
在这里我们结合一个电商销售数据来感受下shift函数的使用。我们有一份客户和购买时间的数据,现在想统计每位用户在今年的平均复购周期和全部用户的平均复购周期。
每位用户的平均复购周期:每两个复购时间之间的天数之和 / 用户总复购次数
全部用户的平均复购周期:全部用户的平均复购周期之和 / 总复购用户数
通过一个例子来解释用户的平均复购周期,假设某位用户购买情况如下:
张三用户的复购间隔分别为:6(1号和7号的间隔),3(7号和10号),10,8;也就是相邻两次购买时间之间的间隔。
那么张三的平均复购周期:(6+3+8+10)/ 4 = 6.75
模拟数据
模拟了一份电商数据,多位用户购买了一次或者多次:
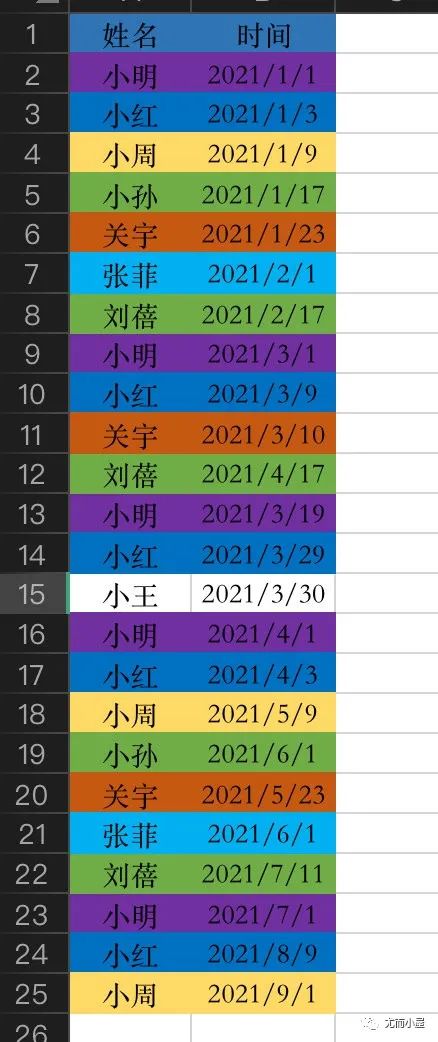
下面通过Pandas来求解每位用户的平均复购周期和全部的平均复购周期
确定哪些用户存在复购行为
复购的用户指的是:在统计时间范围内,存在多次购买的用户。所以我们首先找到那些至少购买两次的用户
统计发现:小王同学只购买了一次,没有复购行为
筛选出复购用户:

从原始数据中提取出复购用户的数据
根据每位用户的购买时间来升序排列

根据每位复购用户的数据移动一个单位
在行方向上移动一个单位:

拼接数据
将排序后的df3和我们根据df3平移后的数据在列方向上拼接起来:
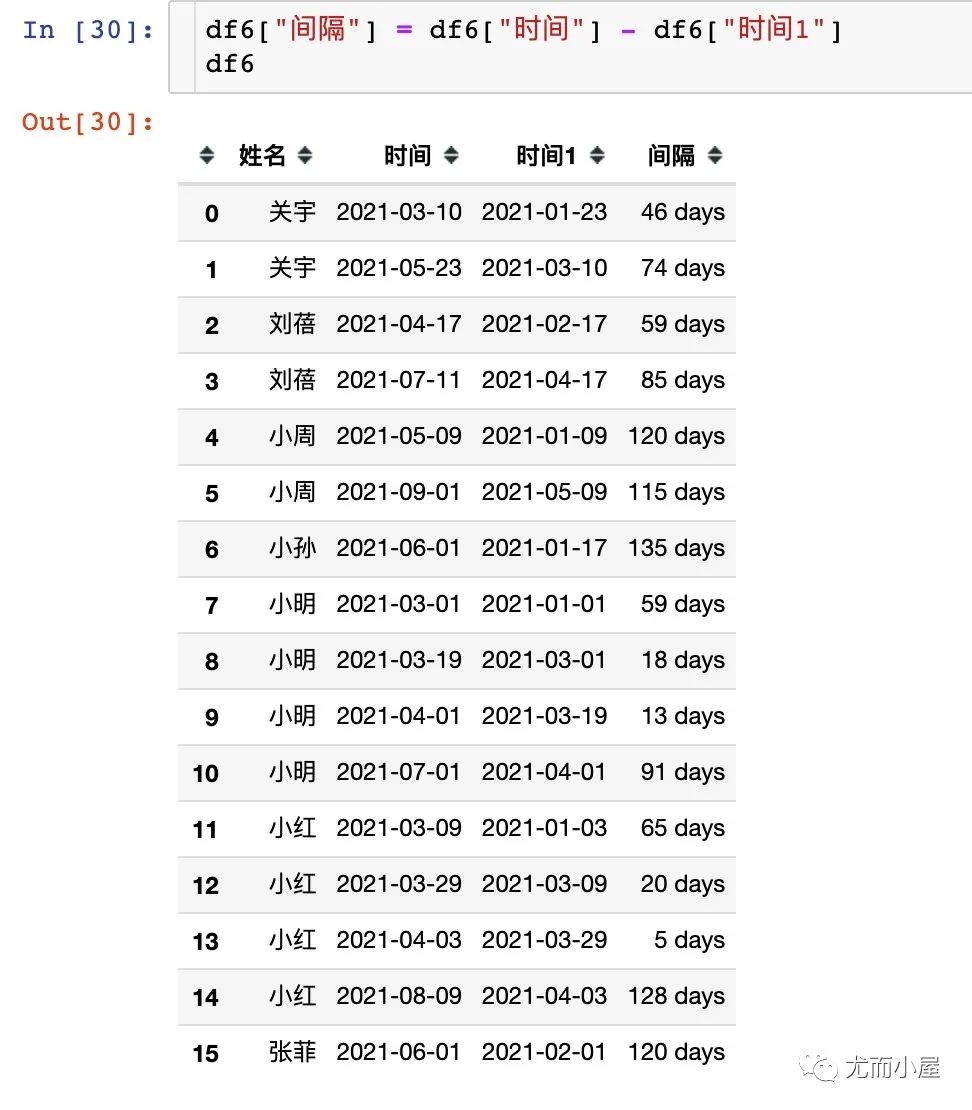
字段时间1相当于每个购买时间的前一个购买时间点

上面的数据框中:
时间: 可以看做是我们的本次购买时间
时间1:上次购买时间。每个用户的第一次购买时间是不存在上次购买时间,所以显示为NaT
将NaT数据删除
使用dropna函数来删除缺失值的数据
求出复购时间间隔
两个字段:时间和时间1的差值,就是每位用户的复购时间间隔,可能存在多个
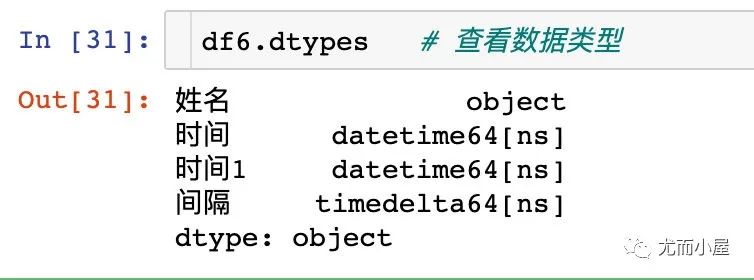
查看数据的字段类型,我们发现间隔这个字段是一个timedelta64[ns]的类型