

ntent="t" style="color:#000000;font-size:16px;font-weight:bold;line-height:22px">「随机小分队」引言
ntent="t" style="color:rgb(51, 51, 51);font-size:15px;line-height:1.6em;margin-bottom:8px">随着语音交互技术的快速发展,2024 年成为语音 AI 领域突破性发展的一年。从 OpenAI Voice 模式到全双工(Fully duplexed)语音转语音系统,技术的进步让 Voice Agent 理能够实时倾听、推理并自然回应,彻底改变了人机交互的体验。
ntent="t" style="color:rgb(51, 51, 51);font-size:15px;line-height:1.6em;margin-bottom:8px">这篇来自 Cartesia 的官方博客系统梳理了语音 AI 的最新进展,从 OpenAI 的 Voice 模式到 Moshi 模型的全双工能力,再到 Sonic TTS 的创新架构,全面解析了语音技术在对话流畅性、延迟优化和多模态协作上的突破。文章还深入探讨了语音 AI 在企业级应用中的潜力,包括客户服务、医疗健康、金融保险等垂直领域的成功案例。
如果你希望了解语音技术如何改变商业和生活场景,这篇文章将为你带来一些启发,enjoy!
步骤如下:
2024 年,对话式语音 AI 实现了突破性进展,协调语音系统的出现将 STT(Speech-to-Text)→ LLM(Large Language Model)→ TTS(Text-to-Speech)模型结合在一起,使系统能够在对话中倾听、推理并作出回应。
OpenAI 在 ChatGPT 中推出的 Voice 模式,使语音转语音(Speech-to-Speech)技术成为现实。这类模型通过音频和文本信息的端到端预训练,不仅能够原生理解文本和音频,还能生成音频和文本标记(Text tokens)。尽管 OpenAI 通过其 Realtime API 的实现尚未完全达到真正的端到端整合(从其演示中对中断处理的挑战可以看出这一点),但这一实现仍然是朝着单一统一模型进行语音交互迈出的重要一步。
与此同时,全双工(Fully Duplexed)语音转语音系统也作为研究成果的形式出现,例如 Kyutai 发布的 Moshi 模型。这类模型“始终在线”的运行机制,与 OpenAI 的系统不同,它们能够在模型输出语音的同时倾听用户的输入。这种突破为未来多模态语音技术的发展提供了全新思路,预示着未来的模型可能将持续接收用户的音频流。
此外,语音领域的新模型架构也变得可行,例如,Cartesia 推出的 Sonic TTS 采用了全新的状态空间模型(SSM)架构,通过自回归方式进行训练。这种架构与近年来流行的基于注意力机制的 Transformer 模型有着显著区别,不仅为部署环境提供了更大的灵活性,还支持内存高效的本地设备部署,同时在质量和延迟性能方面都实现了显著提升。
2024 年,现代 Voice Agent 架构的三个核心组件取得了显著改进,使语音 AI 能够取代传统僵化的“按 1 选择英语”式电话菜单,实现自然对话。
语音转文本(STT)
转录质量已经足够强大,成为设计音频原生应用的标准工具。然而,处理特定领域术语和远场转录的问题仍然具有挑战性。2022 年,OpenAI 的 Whisper 为这一领域奠定了基础,其开源模型基于 68 万小时的多语言音频数据进行训练。此后,Deepgram 的 Nova-2 模型进一步提升了行业标准,在 2024 年实现了单词错误率(Word Error Rate, WER)降低 30% 的突破,为商业应用设立了新标杆。
大型语言模型(LLM)
2024 年,GPT-4o、Llama 3.2、Claude 3.5 Sonnet 和 Gemini 2.0 的发布显著提升了推理能力和效率。LLM 的成本大幅下降,例如 GPT-4 的每百万标记费用从 45 美元降至 Llama 3.1 70B 在 Together AI 上运行时的每百万标记 2.75 美元。语音模型现已支持输入流式处理,使得音频能够在接收来自 LLM 的输入时实时生成,同时在语音片段之间保持一致的韵律。
文本转语音 (TTS)
TTS 模型已经达到生产级成熟度,具备更低的延迟、更自然的语音效果,以及在处理复杂内容(如缩略词和数字表达)时的更高准确性。领先的 TTS 引擎已经将合成语音从机械化的声音转变为真正接近人类的语音。这一进步得益于神经网络架构(如 SSM、Transformer、扩散模型)的创新、训练数据质量和多样性的提升,以及音频编解码器的优化,这对于高效编码和解码数字音频以支持流媒体或存储至关重要。
语音 AI 提供商也从最初专注于专业消费者和语音原生初创公司的定位,逐步转向满足企业需求。语音 AI 系统需要从根本上重新设计,以满足实时交互的严格标准,这些标准远高于传统异步应用的要求。由于实时对话无法编辑或重新生成,基础设施必须提供有保障的正常运行时间、无瑕疵的并发通话处理能力,以及无可妥协的可靠性。
目前大多数 Voice Agent 都建立在核心会话流水线之上,包括语音转文本 (STT)、大语言模型 (LLM) 推理和文本转语音 (TTS)。
尽管这一流水线能够创造自然对话,但企业内部自主开发仍面临诸多挑战:管理实时音频流、处理模型延迟、协调对话轮次以及确保无缝过渡。通常工程团队需要 6 到 12 个月才能完成的工作,现在使用语音编排平台只需数周即可实现。这些平台抽象化了复杂性,让开发者能够专注于打造引人入胜的体验,同时可以灵活组合最佳组件。
LiveKit 和 Daily 等公司开发了开源组件,使用 WebRTC 技术栈实现了跨实时 AI 模型的无缝、低延迟编排。他们的基础设施在确保全球范围内可靠性能的同时,允许开发者保持对全栈的完整定制能力。
此外,Vapi、Retell、Bland 和 Thoughtly 等 Voice Agent 编排平台应运而生,支持快速部署自定义 Agent,并配备了基于 RAG 的知识库和工具调用等高级功能。这些平台还提供额外功能,如语音活动检测 (VAD) 来控制说话者切换,以及情绪识别、中断处理和噪声过滤模型,以促进自然对话。
Hamming、Coval、Vocera 和 Canonical 等新兴可观测性平台构建了完整的评估套件,用于大规模模拟和测量 Voice Agent 质量。
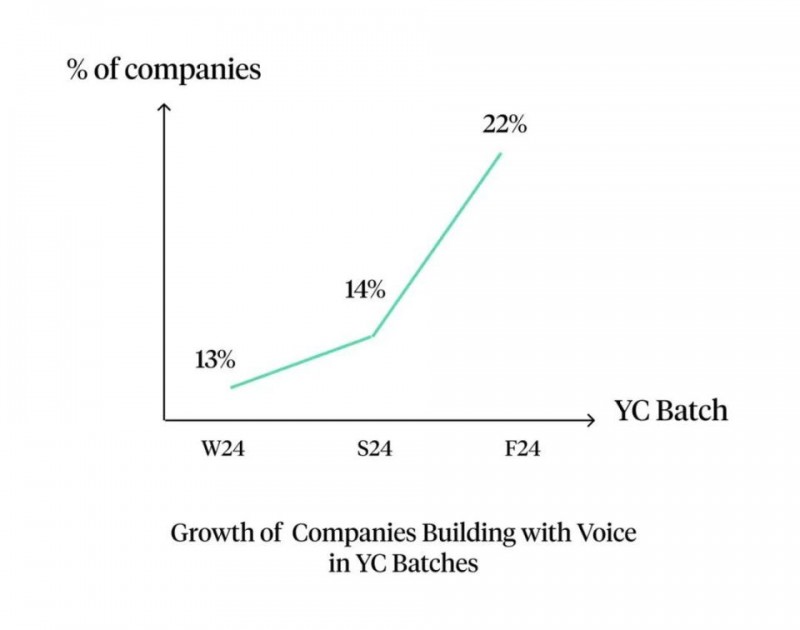
专注于垂直领域的 Voice Agent 创业公司呈现爆发式增长。这一趋势在 Y Combinator 得到了印证:在冬季和秋季批次之间,以语音技术为核心的公司数量增长了 70%。早期采用主要集中在扩充人手不足的服务领域,如全天候客户服务和季节性业务高峰期的运营支持。
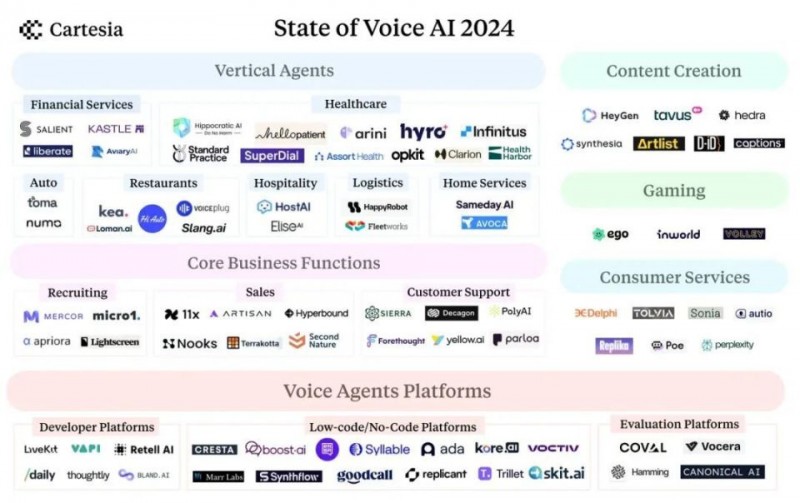
贷款服务领域
Salient 和 Kastle 的 Agent 在贷款服务管理、还款处理方面提供支持,同时负责休眠账户激活和金融产品交叉销售的外联工作。在处理个人身份信息(PII)等敏感数据时,始终遵循高标准的合规要求。
保险领域
Liberate 和 Skit 的 Agent 能够全天候处理理赔、保单续保服务,并为客户详细解释各类保险方案。
医疗健康领域
Abridge 于 2019 年率先将转录技术引入医疗领域,以应对医疗抄写员需求缺口。目前,在 Hello Patient、Hippocratic、Assort Health 和 Superdial 等公司的推动下,全球诊所正在广泛采用 AI 助手,用于就诊预约、用药提醒和账单咨询等服务,并严格保护患者隐私。
物流领域
货运经纪人、第三方物流服务商(3PL)和承运商使用 Happy Robot 和 Fleetworks 来管理查货电话、货物状态更新、支付进度追踪和预约调度等事务。
酒店服务领域
AI 技术在酒店服务中的应用十分广泛,从 Host AI 面向酒店的全渠道 AI 助手,到 Nowadays 的 AI 活动策划服务。Elise AI 的 AI 助手可以与 CRM 系统无缝协作,全面处理从租赁咨询到维护续约的各项业务。
中小企业领域
Goodcall 帮助小型连锁企业轻松部署 AI Agent,实现来电无缝接听。目前,由于人力限制,企业主错失了 60% 的来电机会。Slang 为餐饮行业提供定制解决方案,Numa 则通过与汽车经销商的 CRM 系统对接,利用历史客户互动数据提升客户留存率。Avoca 为暖通空调、管道维修等现场服务行业提供全天候 AI 呼叫中心支持。

Voice Agent 在标准化业务流程中的应用日益普及,并在以下三个关键领域表现尤为突出:
招聘领域
Mercor 和 Micro1 等 AI 面试官通过电话和视频面试显著提升了招聘效率。系统能够基于候选人的背景定制相关问题,与传统的简历筛选方式相比,提供了更深入的洞察。
销售领域
随着电子邮件的效果减弱,11x、Artisan 和 Nooks 等公司通过 AI 销售开发代表(SDR)重新激活了电话销售,用于潜在客户开发和意向筛选。同时,Hyperbound 等平台利用 AI 驱动的角色扮演训练,模拟销售场景,从而提升销售代表的业绩表现。
客户支持领域
Sierra、Decagon、Forethought、Parloa 和 Poly 等 AI 驱动的客户体验平台正在整合语音功能,以支持那些仍然依赖电话进行的大量客户服务互动。
内容创作领域
Heygen、Tavus、D-ID、Synthesia 和 Hedra 等 AI 数字人平台让创作者能够通过单一数字分身生成无限量的配音视频,彻底革新了营销、培训和教育内容的制作方式。Capcut、Canva、Adobe 和 Captions 等创作平台已直接集成 AI 语音功能。同时,《Time》和《The New York Times》等主流媒体也开始采用 AI 为文章配音,使专业级内容创作变得更加普及。
游戏领域
游戏工作室正在利用语音 AI 打造更具沉浸感的体验,通过动态响应型 NPC 实现实时适应玩家互动的目标。Ego 和 Inworld 等平台支持创建丰富的 3D 世界,使 AI 角色能够与玩家自然互动。而实时变声功能则让玩家的声音与游戏角色相匹配,进一步增强了沉浸式体验。
消费者服务领域
语音 AI 让创作者和服务提供商能够指数级扩大个人影响力。例如,Delphi 平台让网红和名人可以同时与数千粉丝互动;Sonia 等平台使教练和治疗师能够提供全天候的个性化指导。Duolingo 和 Khan Academy 等教育平台通过 AI 配音教师扩大了覆盖范围,而 Google 的 NotebookLM 则帮助用户创建文章和书籍的音频摘要。Replika 和 Character AI 提供随时在线的 AI 伴侣服务,而 Tolvia 专门面向老年群体。最后,Quora 的 Poe 和 Perplexity 的语音对话功能,让用户能够通过语音访问广泛的 LLM 内容。
以上内容展示了几个备受关注的重点领域,未来还将有更多创新方向不断涌现。希望在新的一年里,能够支持并见证更多初创企业在这些领域中开拓创新。
随着技术从早期实验阶段走向生产就绪系统,2025 年语音 AI 将在各行各业变得更加强大、可定制且易于使用。
语音转语音(Speech-to-Speech,S2S)模型能够直接将语音输入转换为语音输出,无需经过文本表示环节。尽管 2024 年已经出现了多个 S2S 模型,但我们预计 2025 年将是这项技术的突破之年。这些模型在三个传统上挑战 STT→LLM→TTS 流程的关键维度上展现出令人信服的能力:
延迟:当前最先进的 Voice Agent 的延迟约为 510 毫秒(Deepgram STT:100 毫秒,GPT-4:320 毫秒,Cartesia TTS:90 毫秒),与人类对话约 230 毫秒的延迟相比仍有较大差距。今年发布的早期 S2S 模型(如 Moshi)通过单步处理展现出将延迟降至 160 毫秒的潜力,但仍需要更完善的机制来避免在用户未完成发言时就开始生成回应。
上下文感知:S2S 系统采用同一模型直接处理、理解和生成语音。通过单一模型处理全部内容,S2S 模型能够保留情感、语调和韵律等在文本转换过程中容易丢失的非语言要素。虽然现有系统尝试通过元数据在组件之间传递这些信息,但统一的 S2S 处理将更好地捕捉对话中的细微差别。目前的主要障碍是计算成本,但随着这一问题的解决,性能和效率都将得到显著提升。
中断处理:S2S 模型能够并行处理重叠的语音流,而不是强制要求严格的轮流发言。然而,当前系统在自我语音识别、有限的上下文窗口和重叠音频处理等方面仍面临挑战。预计这些领域将在 2025 年取得重大突破。
2024 年是 Voice Agent 的初步测试阶段,主要用于处理溢出呼叫和具有可预测对话轮次的基础筛选任务。随着盲测 A/B 实验展示出优异的性能指标(包括通话时长、解决率、收入回收率和客户满意度 CSAT),企业对 AI 驱动的语音交互建立了更强的信心。语音 AI 有望成为消费者日常与企业互动的主要界面,应用场景涵盖餐厅预订、医疗预约、账单支付和车管所服务等。
例如,当用户致电航空公司改签机票时,AI Agent可以通过检索增强生成(RAG)技术即时访问乘客记录、航班可用性和航空公司政策,从而实现端到端的服务。这一功能消除了等待时间和部门转接的需求——AI 能够在保持自然对话的同时,同步验证当前预订、识别替代方案、应用相关政策并处理变更。类似于在知识库上微调 LLM 的方式,企业可能希望在其领域或公司特定的词典和风格上微调现有的转录和 TTS 模型,以进一步增强对 AI Agent的信任。AI 解决复杂任务的端到端能力日益受到认可,这一点体现在代理商新的定价模式上——供应商现在提供基于任务成功解决率而非通话时长的结果导向定价。

3. 小型端侧模型将实现随时随地的本地对话
小型设备端 AI 模型因能够解决三个关键挑战而受到广泛关注:无需互联网连接即可运行、通过本地处理降低延迟,以及通过将数据保留在设备上确保隐私安全。这使得语音 AI 能够应用于那些对这些要求不可妥协的场景——从在偏远地区运行的车辆到在信号盲区工作的外勤人员。
随着新型架构、模型量化和蒸馏技术的不断成熟,以及专用边缘 AI 芯片的广泛普及,预计 2025 年将成为设备端语音 AI 的突破之年,最终使本地处理在生产规模上变得切实可行。TensorFlow Lite 和 PyTorch Edge 等框架的进步,通过简化部署和优化流程,加速了这一转变。
2024 年在控制合成语音的细微特征方面取得了重大进展,从情感语气和节奏到精确发音都有显著提升。这些能力已经超越了单纯的语音范畴,实现了语音特征与其他 AI 模态之间的无缝协调。例如,通过语音合成标记语言(SSML),语音中的情感提示现在可以驱动数字化身做出相匹配的肢体语言表达,而 SSML 目前主要负责控制停顿和拼写。创作者将能够将 AI 生成的词语或场景无缝插入现有音频中,新内容会自动采用周围素材的风格和时序。